「総合点」「優良顧客スコア」「偏差値65」── スコアは便利だが、計算式を知らないと誤解する代物。今回は実務でよく使われる代表スコアの定義・読み方・可視化を整理します。
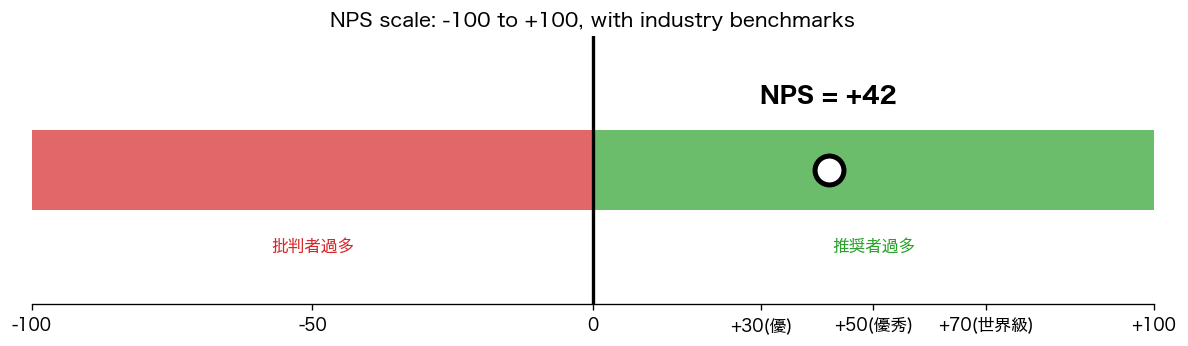
1. NPS()
用途:「友人にどれくらい勧めたいか」を 0-10 で聞いたアンケートの集計。9-10=推奨者、7-8=中立、0-6=批判者。NPS = 推奨者% − 批判者% (-100〜+100 の範囲)。 読み方:0以上で「まあまあ」、+30 で「優秀」、+50 で「世界級」。Apple は 70+。 落とし穴:中立7-8がカウントされない、業界によって基準が違う。
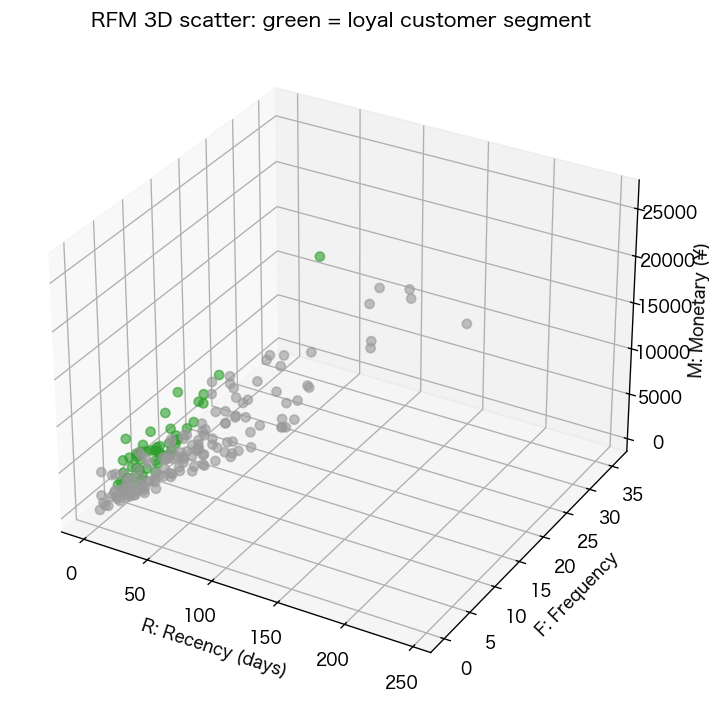
2. 分析
用途:CRM での顧客ランク付け。Recency(最終購入から何日)、Frequency(購入回数)、Monetary(購入総額)の3軸を 1-5 等分してスコア化。 強み:顧客セグメントが自動で出せる(111 = 優良ロイヤル、555 = 離反顧客)。 弱み:3軸のしきい値の置き方で結果が大きく変わる。
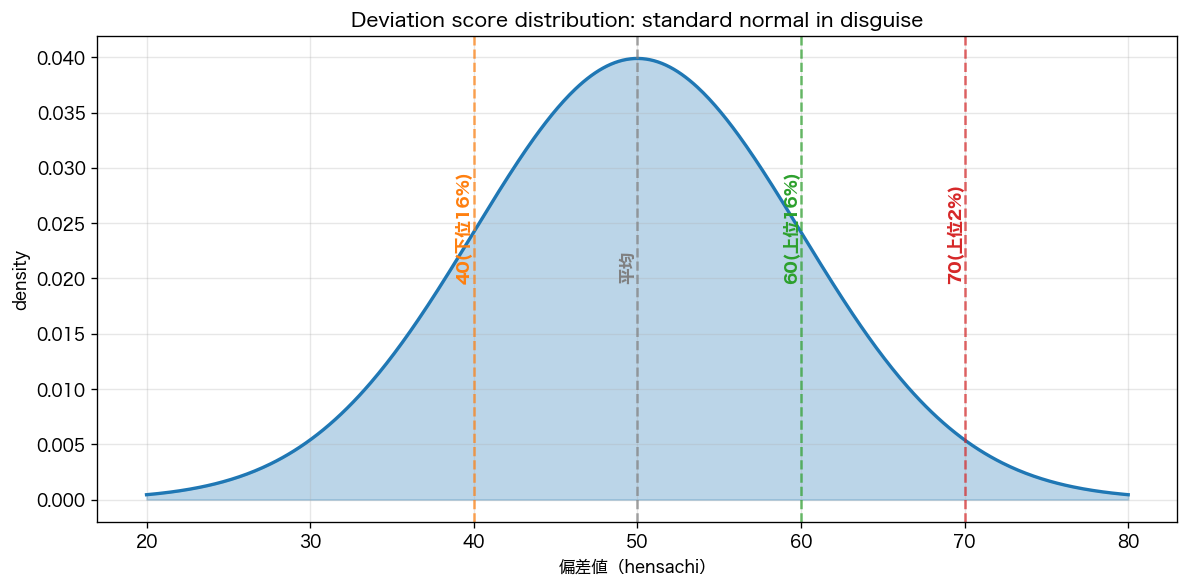
3. 偏差値(z-score の応用)
用途:日本の受験界の標準。偏差値 = 50 + 10 × (個人 − 平均) / 標準偏差。 読み方:50=平均、60=上位16%、70=上位2%。 落とし穴:母集団が変われば同じ点数でも偏差値が変わる、外れ値の影響あり。
4. z-score(標準化スコア)
用途:単位の違うデータを比較可能にする。z = (x − μ) / σ。-3〜+3 の範囲に収まることが多い。 強み:複数指標を統合する際の標準前処理(前の正規化)。
5. t値・p値(A/Bテストで頻出)
用途:「2グループの平均に有意差があるか」の統計検定。p < 0.05 で「偶然じゃなさそう」とみなす慣例。 強み:意思決定に客観性を与える。 弱み:サンプルサイズが大きいと小さな差でも有意になる ─ 効果量(Cohen's d)と併用するのが正解。
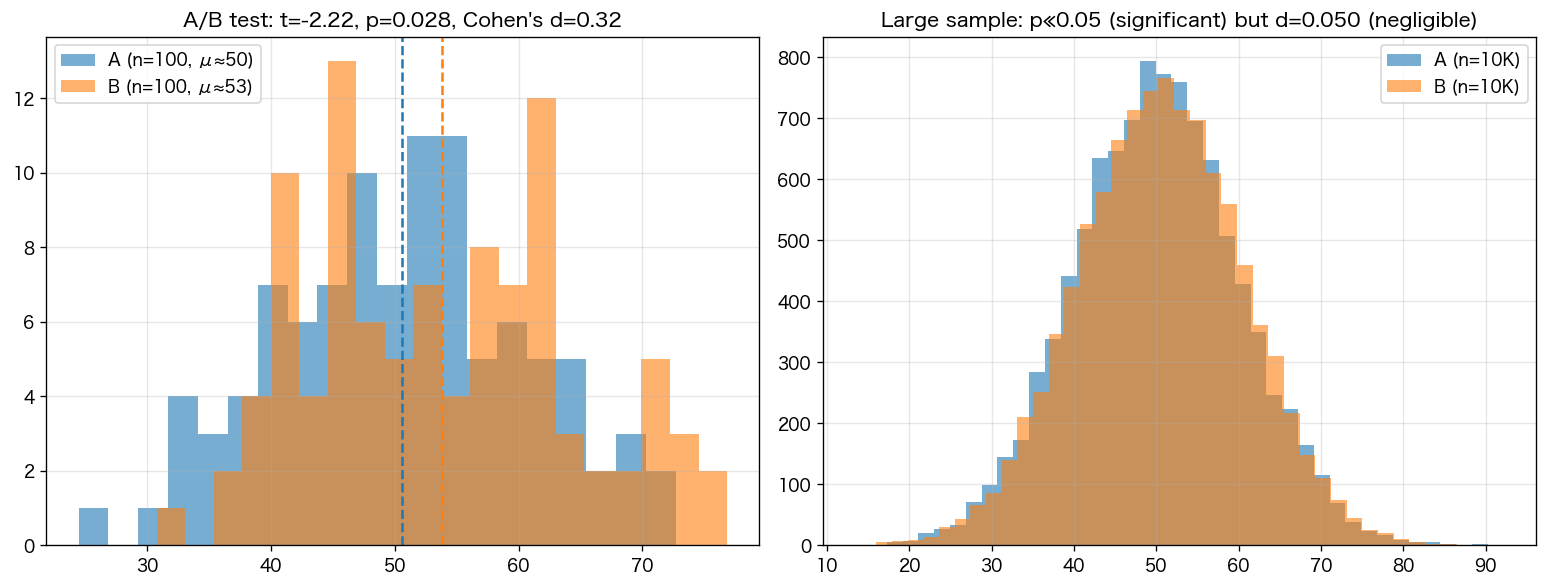
6. 効果量(Cohen's d、Hedges' g)
用途:「実用的に意味のある差か」を測る。d = (μ₁ − μ₂) / σ_pooled。 目安:d=0.2(小)、0.5(中)、0.8(大)。p値とセットで報告するのが現代の標準。
import pandas as pd
# 仮の購買データdf = pd.DataFrame({ "customer_id": [1, 2, 3, 1, 2, 4, 1], "date": pd.to_datetime(["2026-04-01", "2026-04-15", "2026-03-20", "2026-05-01", "2026-04-22", "2026-04-25", "2026-05-03"]), "amount": [10000, 5000, 3000, 8000, 6500, 4000, 12000],})
today = pd.Timestamp("2026-05-07")
rfm = df.groupby("customer_id").agg( recency=("date", lambda d: (today - d.max()).days), frequency=("date", "count"), monetary=("amount", "sum"),)
# 各軸を5段階にrfm["R"] = pd.qcut(rfm["recency"], 5, labels=[5,4,3,2,1], duplicates="drop")rfm["F"] = pd.qcut(rfm["frequency"], 5, labels=[1,2,3,4,5], duplicates="drop")rfm["M"] = pd.qcut(rfm["monetary"], 5, labels=[1,2,3,4,5], duplicates="drop")rfm["RFM"] = rfm["R"].astype(str) + rfm["F"].astype(str) + rfm["M"].astype(str)print(rfm)次回予告
EP.10 は階層系:ツリー・サンバースト・デンドログラム。組織図・カテゴリ階層・クラスタリング結果を見せる定番。
この記事の感想を教えてください
あなたの 1 クリックで、本当にこの記事は更新されます。「もっと詳しく」「続編希望」が一定数集まった記事は、 ふくふくが 実際に内容を拡充したり続編記事を公開 します。 送信したリアクションはお使いのブラウザに記録され、再カウントされません。