「数字を小さい順に並べる」── たったこれだけのことに、コンピュータサイエンスは 70 年以上かけて、何十種類ものアルゴリズムを発明してきました。なぜそんなに多いのか?答えは「入力の性質や制約が違うと、最適な解き方が違う」から。今回は代表的な5〜6種類を実際に動かして、の違い・歴史的な背景・最近の進化までを追います。
① O(n²) と の差を肌で感じる(10万要素で何秒違うか)。② バブルソート・選択ソート・挿入ソート・マージソート・クイックソート・Timsort/Powersort の特徴と発明年。③ 「なぜ Python の sorted() は速いのか」が分かる。
Step 0: なぜ何十種類もあるのか — ソートアルゴリズム年表
ソートの歴史を辿ると、「制約が変わるたびに新しいアルゴリズムが必要だった」ことが分かります。1945年から2022年まで、80年近く発明され続けています。
| 年 | アルゴリズム | 発明者・出処 | 計算量(平均) | ポイント |
|---|---|---|---|---|
| 1945–1950s | 選択ソート / 挿入ソート | ─(自然発生) | O(n²) | メモリ極小時代の主役。追加メモリ不要 |
| 1959 | シェルソート | Donald Shell | O(n^1.3) 程度 | 挿入ソートを飛び飛びに改良。磁気テープ向き |
| 1962 | クイックソート | Tony Hoare(英) | O(n log n) | 分割統治の発明。今でも実用最速級 |
| 1964 | ヒープソート | J.W.J. Williams | O(n log n)(最悪も) | 優先度付きキューと一緒に発明 |
| 1969 | マージソート(体系化) | Knuth(von Neumannの着想) | O(n log n) | 安定ソートの代表。並列化しやすい |
| 2002 | Timsort | Tim Peters / Python | O(n log n) / 整列済み O(n) | Python 標準。部分整列を活用 |
| 2018 | Pdqsort | Orson Peters | O(n log n) | Rust 標準。敵対的入力を検出 |
| 2022 | Powersort | Munro & Wild | O(n log n) | Timsort のマージ戦略を最適化。Java 21 で標準採用 |
「全部の場合に最速」のソートは存在しません(情報理論で下限 Ω(n log n) が証明されている)。だから「特定の入力に強いソート」が次々生まれる:ほぼ整列済みなら Timsort、巨大データなら radix、分散環境なら sample sort、最悪保証が必要なら heap、など。
Step 1: 4 つの基礎ソートを実装
まず教科書に出る4つを Python で実装。動作はどれも同じ「小さい順に並べる」、計算量だけ違う。
def bubble_sort(a): a = a.copy() n = len(a) for i in range(n): for j in range(0, n-i-1): if a[j] > a[j+1]: a[j], a[j+1] = a[j+1], a[j] return a
def selection_sort(a): a = a.copy() for i in range(len(a)): m = i + a[i:].index(min(a[i:])) a[i], a[m] = a[m], a[i] return a
def insertion_sort(a): a = a.copy() for i in range(1, len(a)): key = a[i]; j = i - 1 while j >= 0 and a[j] > key: a[j+1] = a[j]; j -= 1 a[j+1] = key return a
def merge_sort(a): if len(a) <= 1: return a mid = len(a) // 2 left, right = merge_sort(a[:mid]), merge_sort(a[mid:]) out, i, j = [], 0, 0 while i < len(left) and j < len(right): if left[i] <= right[j]: out.append(left[i]); i += 1 else: out.append(right[j]); j += 1 return out + left[i:] + right[j:]
# 動作確認import randomdata = [random.randint(0, 100) for _ in range(10)]print("元:", data)print("バブル:", bubble_sort(data))print("マージ:", merge_sort(data))Step 2: 計算量の差を実測する
サイズ n を変えて時間を測定。O(n²) は n を10倍にすると100倍遅くなる、O(n log n) は約 13 倍。これを実際にグラフで見ます。
import time, randomimport matplotlib.pyplot as plt
def measure(sort_fn, n, trials=3): ts = [] for _ in range(trials): data = [random.random() for _ in range(n)] t0 = time.perf_counter() sort_fn(data) ts.append(time.perf_counter() - t0) return min(ts)
sizes_sq = [200, 500, 1000, 2000, 4000, 8000]sizes_nlogn = [1000, 5000, 20000, 100000, 500000]
results = {}for sf in [bubble_sort, selection_sort, insertion_sort]: results[sf.__name__] = [measure(sf, n) for n in sizes_sq]results["merge_sort"] = [measure(merge_sort, n) for n in sizes_nlogn]results["sorted (Timsort)"] = [measure(lambda a: sorted(a), n) for n in sizes_nlogn]
plt.figure(figsize=(10, 6))for name in ["bubble_sort", "selection_sort", "insertion_sort"]: plt.loglog(sizes_sq, results[name], "o-", label=f"{name} (O(n²))")for name in ["merge_sort", "sorted (Timsort)"]: plt.loglog(sizes_nlogn, results[name], "s-", label=f"{name} (O(n log n))")plt.xlabel("Input size n"); plt.ylabel("Time (sec, log)")plt.title("Step 2: O(n²) vs O(n log n) — measured")plt.legend(); plt.grid(alpha=0.3, which="both")plt.show()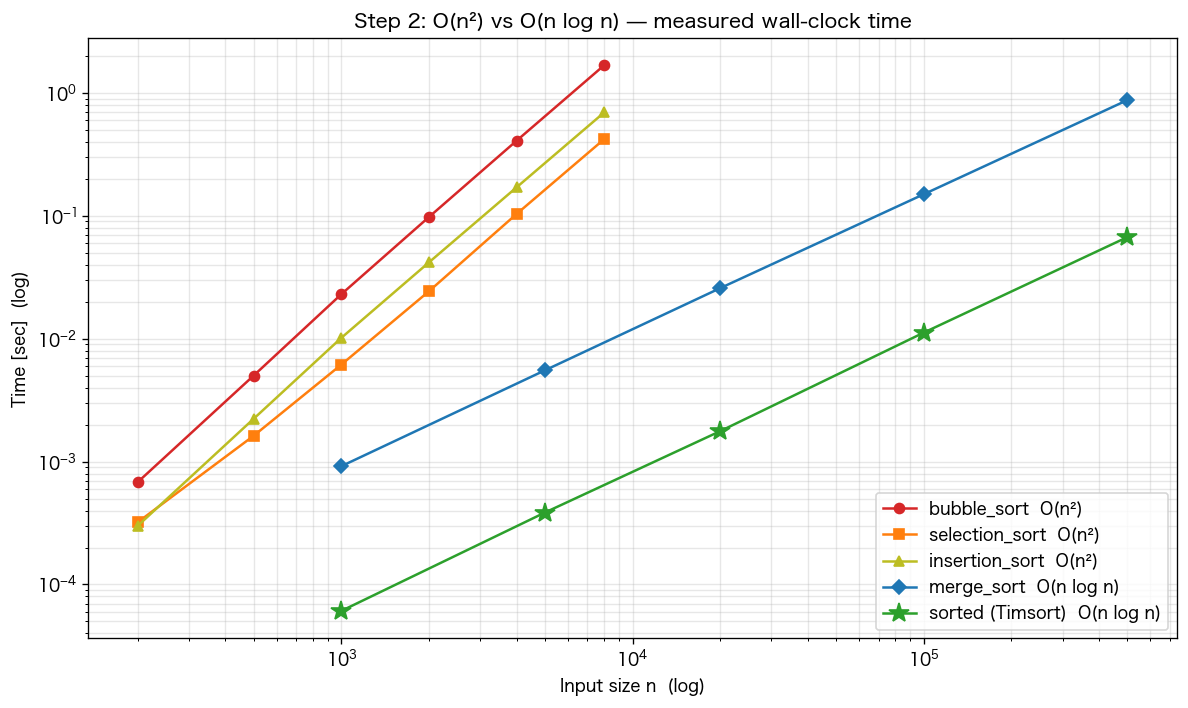
100万要素のソート、O(n²) なら 1日かかるのが O(n log n) なら数秒。アルゴリズムの選択は、現代のソフトウェアでは「動く / 動かない」の境目です。
Step 3: クイックソート — 分割統治の発明
1962 年、英国の Tony Hoare が発明したクイックソートは、いまでも「実用最速級」と言われ続けています。アイデアはシンプル:ピボットを選んで、それより小さいグループ・大きいグループに分ける。これを再帰。
import randomdef quick_sort(a): if len(a) <= 1: return a pivot = a[len(a)//2] left = [x for x in a if x < pivot] mid = [x for x in a if x == pivot] right = [x for x in a if x > pivot] return quick_sort(left) + mid + quick_sort(right)
print(quick_sort([3,6,1,8,2,9,4,7,5]))理論上の計算量はマージソートと同じ O(n log n) ですが、メモリアクセスがキャッシュに優しいこと、追加メモリが O(log n) で済むこと、定数倍が小さいことから、ほとんどのケースでマージより速くなります。ただし最悪 O(n²)。
Step 4: 「現実は半分くらい並んでる」を活かす Timsort
2002 年、Tim Peters は気づきました:現実のデータには「すでに並んでる連続部分」(run)が頻繁にある。例:ログを時系列で集めたあと逆順を混ぜる、 を読み込む、など。Timsort は run を検出して、それをマージするだけで済ませます。これが Python sorted() が異常に速い理由。
import random, time
n = 200000# 完全にランダムrandom_data = [random.random() for _ in range(n)]# 半分は既に並んでるpartial_data = sorted(random.random() for _ in range(n//2)) + [random.random() for _ in range(n//2)]
for label, data in [("random", random_data), ("partial", partial_data)]: t0 = time.perf_counter() sorted(data) print(f"sorted({label}): {time.perf_counter()-t0:.3f} s") t0 = time.perf_counter() quick_sort(data) print(f"quick({label}): {time.perf_counter()-t0:.3f} s")Powersort(2022, Munro & Wild) は Timsort の「マージ順序選択」が最適でなかったことを数学的に証明し、新しいルールを提示。Java 21 で標準採用。「20年使われたアルゴリズムにまだ改善余地があった」という、研究の面白さの典型例。
Step 5: 「比較しない」ソート ─ Radix sort
ここまで全部「2要素を比べる」ソートでした。でも入力が整数のように構造を持つ場合、比較せずにバケットに振り分けることで、理論限界 Ω(n log n) を超えられます。例:32bit整数なら O(n) で並ぶ。
def radix_sort(a): a = a.copy() if not a: return a max_val = max(a) exp = 1 while max_val // exp > 0: # 桁ごとにバケットに振り分ける buckets = [[] for _ in range(10)] for x in a: buckets[(x // exp) % 10].append(x) a = [x for b in buckets for x in b] exp *= 10 return a
print(radix_sort([170, 45, 75, 90, 802, 24, 2, 66]))# → [2, 24, 45, 66, 75, 90, 170, 802]1億個の 32bit 整数なら、Timsort より radix の方が速い。条件が違うと最適アルゴリズムが変わる典型例です。
自由研究の提案
① 安定ソート: バブル・挿入・マージは「同値の順序を保つ」(安定)、選択・クイックは保たない。データに名前と年齢が混じってるとき、まず名前でソートしてから年齢でソートすると、結果がどう違うか比べる。 ② 並列ソート: マージソートは分割した各部分を独立に処理できる。Python の `multiprocessing` を使って2スレッド・4スレッドで実行し、速度向上を測る(GIL の影響も観察)。 ③ メモリアクセスの計測: クイックソートは速いが「キャッシュに優しい」と言われる。`numpy` で配列のソートを比較し、なぜ C 実装の方が桁違いに速いか考える。 ④ 量子ソート: 2024年に話題の「量子コンピュータでソートを高速化できるか」を調べる ─ 答えは「理論的には Ω(n log n) が下限なので大幅な高速化はできない」。ただし量子の優位がある問題(探索など)と何が違うか考えてみる。
次回予告
EP.15 は探索アルゴリズム。線形 → 二分 → ハッシュ → / → A*、そして近年話題の「ベクトル検索(・)」と「量子探索(Grover アルゴリズム)」まで。同じ「探す」に何種類のアプローチがあるか、なぜそれが必要かを追います。
この記事の感想を教えてください
あなたの 1 クリックで、本当にこの記事は更新されます。「もっと詳しく」「続編希望」が一定数集まった記事は、 ふくふくが 実際に内容を拡充したり続編記事を公開 します。 送信したリアクションはお使いのブラウザに記録され、再カウントされません。