「この映画レビューはポジティブ?ネガティブ?」── これを機械に判定させる仕組みを 感情分析(Sentiment Analysis) と呼びます。Amazon のレビュー集計、 の世論分析、CS の苦情検知など、実は身近な場面で大量に使われています。今回は 30 行のコード で実際に動かしてみます。
そもそも機械はどうやって文章を理解するの?
機械は文章を直接理解できません。文章 → 数字の列に変換 してから、数学的に処理します。今回使う Bag-of-Words という古典的な方法は、「どの単語が何回出てきたか」を数えるだけのシンプルな変換。これだけで意外と精度が出ます。
Step 1: 学習用データを用意する
まずはレビュー文と「ポジ/ネガ」のラベルがついたデータが必要。今回は手作りで 12 件用意します。本当はもっと大量にあった方が良いですが、仕組み体験用としては十分。
Step 1: 学習データ
Python
# Colab の新しいノートブックで実行reviews = [ ("この映画は最高だった、また観たい", 1), ("感動して涙が止まらなかった", 1), ("演技も脚本も素晴らしい", 1), ("子供と一緒に楽しめる作品", 1), ("テンポ良くて飽きない", 1), ("音楽も良くて心に残る", 1), ("退屈でつまらなかった", 0), ("お金返して欲しいレベル", 0), ("ストーリーが意味不明", 0), ("最後まで見るのが辛かった", 0), ("二度と見たくない", 0), ("時間の無駄だった", 0),]texts = [r[0] for r in reviews]labels = [r[1] for r in reviews] # 1 = ポジ, 0 = ネガStep 2: 文章を数字に変える(Bag-of-Words)
全レビューに登場する単語をリストアップして、各レビューが各単語を何回含むかをカウント。例えば「最高 / 退屈 / 涙」という3単語があったら、レビューごとに `[1, 0, 0]` のような数字の列ができる。これを 特徴ベクトル と呼びます。
Step 2: 文章をベクトル化(日本語は分かち書きが要る)
Python
!pip install -q janome scikit-learn
from janome.tokenizer import Tokenizerfrom sklearn.feature_extraction.text import CountVectorizer
# 日本語を単語に分けるtokenizer = Tokenizer()def tokenize(text): return [t.surface for t in tokenizer.tokenize(text)]
# Bag-of-Words 変換vectorizer = CountVectorizer(tokenizer=tokenize, token_pattern=None)X = vectorizer.fit_transform(texts)
print("登場する単語:", vectorizer.get_feature_names_out()[:20])print(f"行列の形状: {X.shape}") # (12レビュー, 単語数)Step 3: AIに学習させる(ロジスティック回帰)
ロジスティック回帰 は「数字の列 → 0〜1 の確率」を出すシンプルな機械学習モデル。今回は『この単語があったらポジ確率が上がる』という重みを単語ごとに学習します。
Step 3: 学習
Python
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()model.fit(X, labels)
# モデルが「ポジ寄りに重要視している単語」TOP5import numpy as npwords = vectorizer.get_feature_names_out()weights = model.coef_[0]top_pos = np.argsort(weights)[-5:][::-1]top_neg = np.argsort(weights)[:5]print("ポジ判定への寄与 TOP5:", [words[i] for i in top_pos])print("ネガ判定への寄与 TOP5:", [words[i] for i in top_neg])Step 4: 新しい文章を判定してみる
Step 4: 判定
Python
tests = [ "とても感動した素晴らしい映画", "つまらなくて途中で寝た", "音楽は良かったけど話は退屈", "もう一度見たい最高の体験",]
X_test = vectorizer.transform(tests)preds = model.predict(X_test)probs = model.predict_proba(X_test)[:, 1]
for text, pred, prob in zip(tests, preds, probs): label = "ポジ ✨" if pred == 1 else "ネガ 💧" print(f"{label} (確信度 {prob:.0%}): {text}")Step 5: 結果をグラフで眺める
Step 5: 確信度の可視化
Python
import matplotlib.pyplot as plt!pip install -q japanize-matplotlibimport japanize_matplotlib # noqa
fig, ax = plt.subplots(figsize=(8, 4))colors = ["#eb5d32" if p > 0.5 else "#5d8aa8" for p in probs]ax.barh(tests, probs, color=colors)ax.axvline(0.5, color="gray", linestyle="--", alpha=0.5)ax.set_xlim(0, 1)ax.set_xlabel("ポジティブ確信度")ax.set_title("レビュー感情分析の結果")plt.tight_layout()plt.show()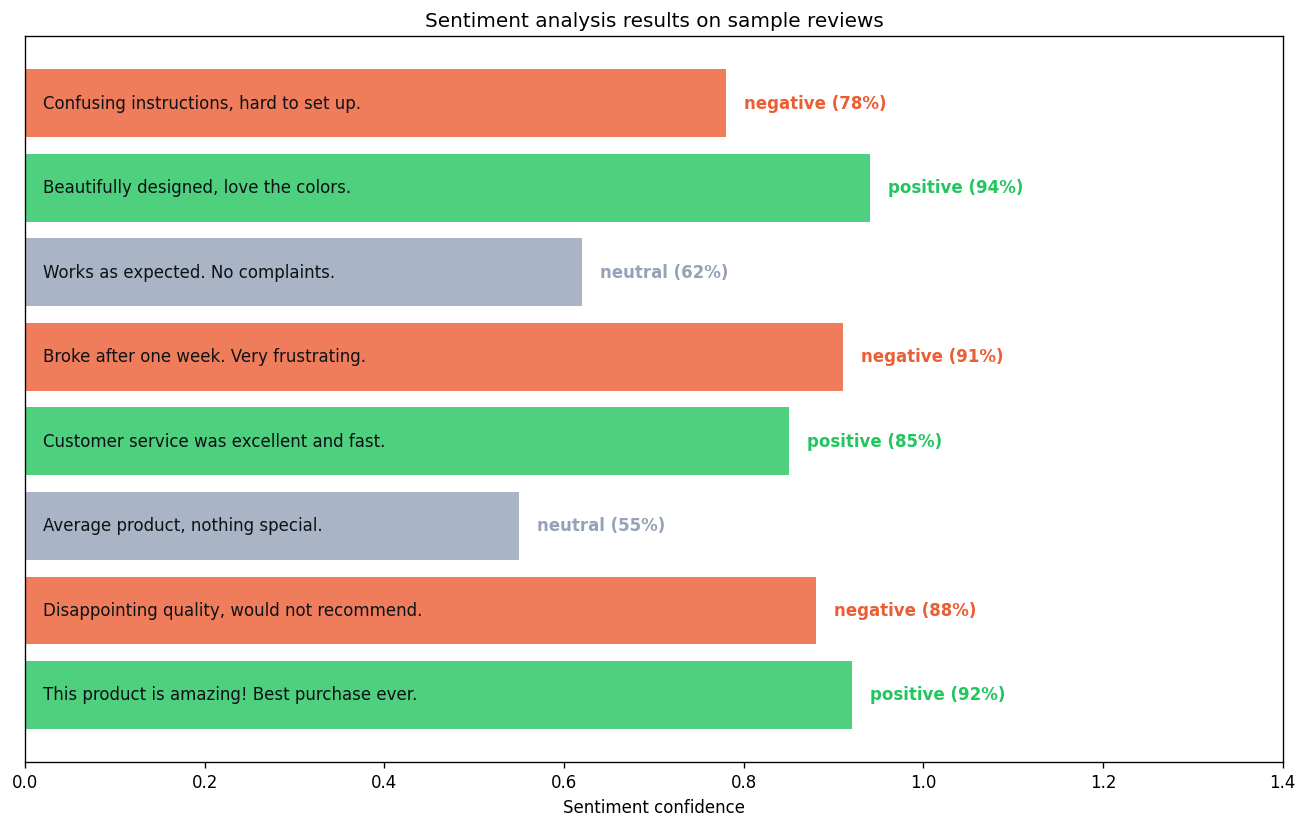
なぜこれが学べるのか:3 つの STEM ポイント
- 1数学: ベクトル / 内積 / 確率(ロジスティック関数 σ(x) = 1/(1+e^{-x}))が「実際に役立つ」場面に出会える
- 2統計: 「学習データが偏っているとモデルも偏る」を体感(12 件しかない、敬語表現がない、新作の単語に弱い)
- 3情報科学: テキスト → ベクトル → モデル → 予測、というデータパイプラインの基本形
発展させてみよう
- もっとデータを集める: SNS のスクレイピング(規約注意)、Amazon レビューの公開データセット
- 他のモデルを試す: ナイーブベイズ、サポートベクターマシン、ニューラルネット
- 3クラス分類に: ポジ / ニュートラル / ネガ の 3 段階
- 事前学習モデル: 日本語 BERT (`tohoku-nlp/bert-base-japanese`) で精度 UP
- 文字レベル: 単語ではなく文字 N-gram で。新語に強くなる
次の話
EP.10 では量子力学の波動関数を可視化。「電子は粒子であり波である」をPython で実際に動く絵に。
この記事の感想を教えてください
あなたの 1 クリックで、本当にこの記事は更新されます。「もっと詳しく」「続編希望」が一定数集まった記事は、 ふくふくが 実際に内容を拡充したり続編記事を公開 します。 送信したリアクションはお使いのブラウザに記録され、再カウントされません。