「」と聞くと難しそうですが、入口は意外と単純。今回は の世界で最も有名な「アヤメ(iris)データセット」を使って、3品種を見分ける分類モデルを15分で作ります。1936年に統計学者 Ronald Fisher が論文に使ったこのデータが、今も入門の定番。
① 機械学習の「教師あり学習」の流れを体感する ② アヤメ150株のデータで品種分類器を作る ③ 決定木とランダムフォレストの違いを見る ④ 「正答率」だけじゃない評価方法(混同行列)を知る
Step 1: アヤメデータって何?
3品種 × 50株 = 150株のアヤメについて、以下の4つの数字が記録されています: - がく片の長さ(cm) - がく片の幅(cm) - 花弁の長さ(cm) - 花弁の幅(cm) これらの数字だけから「setosa / versicolor / virginica のどれか」を当てるのが今回の課題。人間が見ても判別が難しいけど、コンピュータは数字のパターンから学習できる。
Step 2: データを見てみる
from sklearn.datasets import load_irisimport pandas as pd
iris = load_iris()df = pd.DataFrame(iris.data, columns=iris.feature_names)df["species"] = [iris.target_names[t] for t in iris.target]
print(df.head())print(f"\n品種別個数:\n{df['species'].value_counts()}")
# 散布図で品種を色分けimport seaborn as snsimport matplotlib.pyplot as pltsns.pairplot(df, hue="species", height=2.0)plt.show()散布図行列を見ると、setosa は完全に分離できる(簡単)。versicolor と virginica は重なる部分がある(難しい)。この「線で引けるか引けないか」を、数学とアルゴリズムで自動化するのが機械学習。
Step 3: 決定木で学習・予測
from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.tree import DecisionTreeClassifier, plot_treefrom sklearn.metrics import accuracy_score, confusion_matriximport matplotlib.pyplot as plt
iris = load_iris()
# 訓練 70% / テスト 30%X_train, X_test, y_train, y_test = train_test_split( iris.data, iris.target, test_size=0.3, random_state=42)
# 学習model = DecisionTreeClassifier(max_depth=3, random_state=42)model.fit(X_train, y_train)
# 予測 + 評価predictions = model.predict(X_test)print(f"正答率: {accuracy_score(y_test, predictions):.2%}")
# 混同行列(どこで間違えたか)cm = confusion_matrix(y_test, predictions)print(f"\n混同行列:\n{cm}")
# 決定木を可視化plt.figure(figsize=(14, 8))plot_tree(model, feature_names=iris.feature_names, class_names=iris.target_names, filled=True)plt.title("Decision Tree learned for iris")plt.show()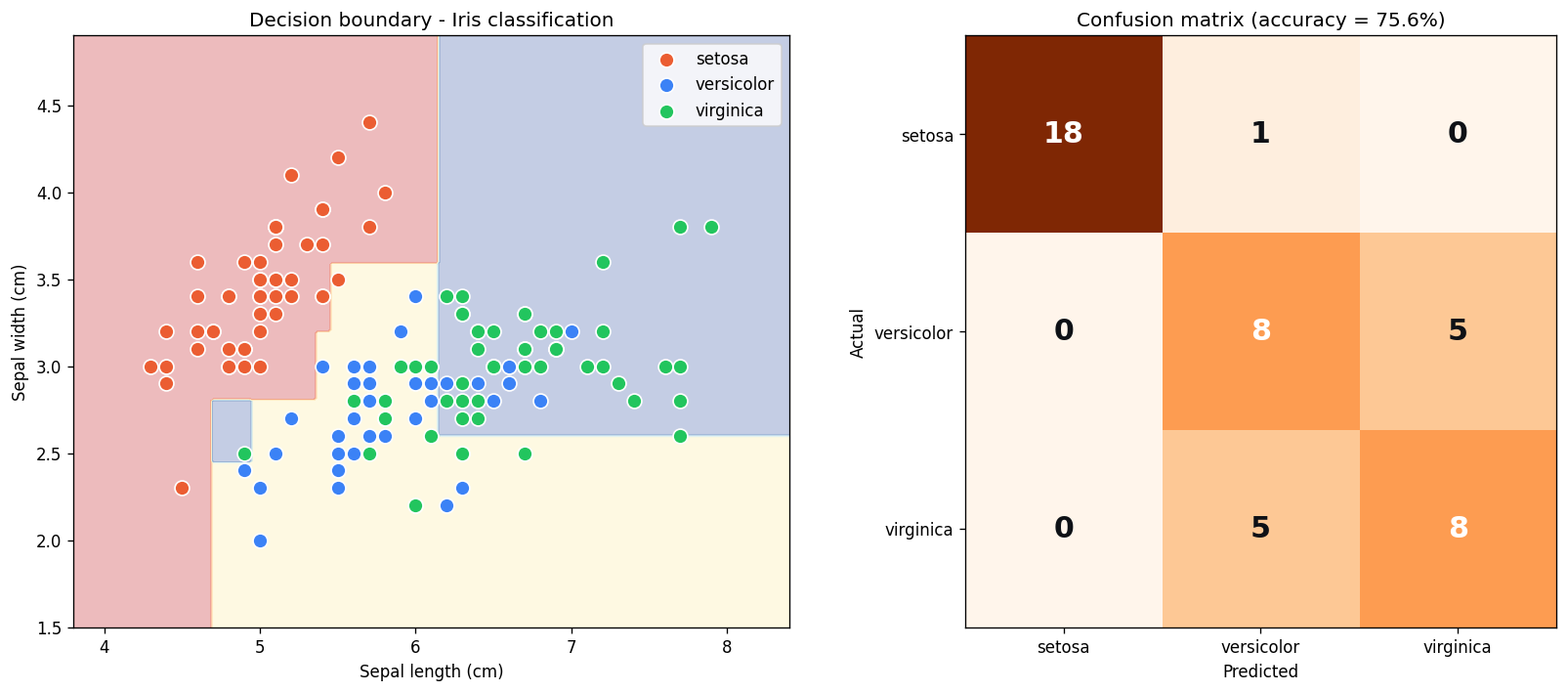
Step 4: 「if 文」の自動生成として理解する
決定木が学習したのは、こういう if-else の連鎖: ``` if 花弁の長さ < 2.5: setosa elif 花弁の長さ < 4.7 と 花弁の幅 < 1.7: versicolor elif: virginica ``` 人間がいちいち if 文を書く代わりに、データから自動で if の条件を発見するのが決定木の仕事。
Step 5: ランダムフォレストでもっと強く
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=100, random_state=42)rf.fit(X_train, y_train)predictions_rf = rf.predict(X_test)print(f"ランダムフォレストの正答率: {accuracy_score(y_test, predictions_rf):.2%}")
# どの特徴量が重要かimportance = rf.feature_importances_for name, imp in zip(iris.feature_names, importance): print(f" {name}: {imp:.3f}")ランダムフォレストは「どの数字が判別に効いたか」も教えてくれる。アヤメの場合、花弁の長さと幅が圧倒的に重要、というのが分かる。これは生物学的にも正しく、品種改良に使われている。
自由研究のヒント
- 自分の手書き数字を分類:sklearn の `load_digits` で 0〜9 の手書き数字データセット。同じ流れで作れる
- ワインの品質予測:`load_wine` でワインの化学成分から品質を予測
- 自分のデータで:例:好きな曲 50曲 + 嫌いな曲 50曲を 化、特徴を機械学習で抽出
- 他のアルゴリズムも試す:SVM・k近傍法・ニューラルネットなど、scikit-learn には20+の分類器が揃ってる
次回予告
EP.08 は画像処理。OpenCV で顔認識・画像加工を試します。
この記事の感想を教えてください
あなたの 1 クリックで、本当にこの記事は更新されます。「もっと詳しく」「続編希望」が一定数集まった記事は、 ふくふくが 実際に内容を拡充したり続編記事を公開 します。 送信したリアクションはお使いのブラウザに記録され、再カウントされません。